
The K-Fold Cross Validation in Machine Learning
Takeaways from the article
Machine learning algorithms, apart from many uses, are also used to extract patterns from data or predict certain continuous or discrete values. It is also important to understand that the model that is built with respect to the data is just right – it doesn’t overfit or underfit. ‘Overfitting’ and ‘underfitting’ are two concepts in Machine Learning that deal with how well the data has been trained and how accurately the data has been predicted. The Over fitting includes a value Hyperparameter, to see how the algorithm behaves.
Underfitting in Machine Learning
Given a dataset, and an appropriate algorithm to train the dataset with, if the model fits the dataset rightly, it will be able to give accurate predictions on never-seen-before data.
On the other hand, if the Machine Learning model hasn’t been trained properly on the given data due to various reasons, the model will not be able to make accurate or nearly good predictions on the data.
This is because the model would have failed to capture the essential patterns from the data.
If a model that is being trained is stopped prematurely, it can lead to underfitting. This means data won’t be trained for the right amount of time, due to which it won’t be able to perform well with the new data. This would lead to the model not being able to give good results, and they could not be relied upon.
The dashed line in blue is the model that underfits the data. The black parabola is the line of data points that fits the model well. 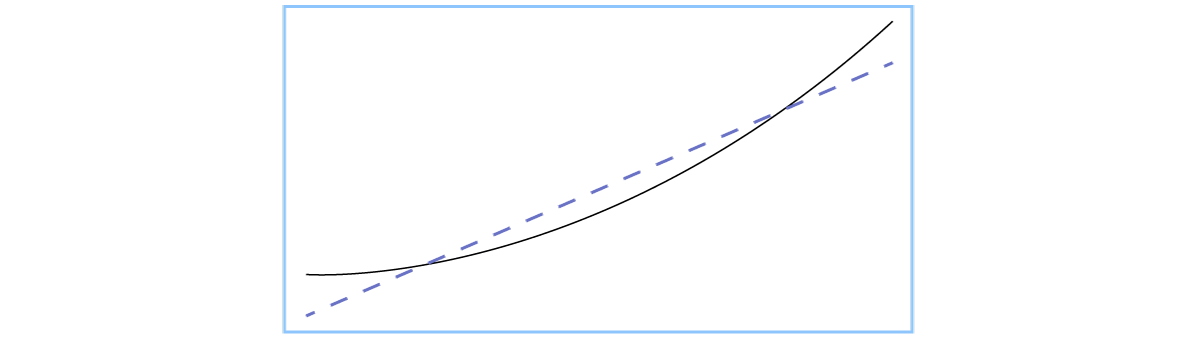
This is just the opposite of underfitting. It means that instead of extracting the patterns or learning the data just right, it learns too much. This means all the data is basically captured, including noise (irrelevant data, that wouldn’t contribute to the prediction of output when new data is encountered) thereby leading to not being able to generalize the model to new data. The model, during training, performs well, and learns all data points, literally memorizing the data that it has been given. But when it is in the testing phase or a new data point is introduced to it, it fails miserably. The new data point will not be captured by an overfit machine learning model.
The model, during training, performs well, and learns all data points, literally memorizing the data that it has been given. But when it is in the testing phase or a new data point is introduced to it, it fails miserably. The new data point will not be captured by an overfit machine learning model.
Note: In general, more the data, better the training, leading to better prediction results. But it should also be made sure that the model is not just capturing all points, instead it is learning, thereby removing the noise present in the data.
Before exposing the model to the real world, the training data is divided into two parts. One is called the ‘training set’ and the other is known as the ‘test set’. Once the training is completed on the training dataset, the test set is exposed to the model to see how it behaves with newly encountered data. This gives a sufficient idea about how accurately the model can work with new data, and its accuracy.
Hyperparameters are values that are used in Machine Learning, set by the user by performing a few trails, to see how the algorithm behaves. Some examples include ridge regression and gradient descent.
Hyperparameters depend on various factors like the algorithm in hand, the data provided, and so on. The optimal value of hyperparameter can be found only through trial and error method. This method is known as hyperparameter tuning.
To check the value of the hyperparameter, and to tune the hyperparameter, the test set (the data set which is used to see how the model works on new data) is constantly used, thereby making the model develop an affinity to the test data set. When this happens, the test set almost becomes the training set, and the test data set can’t be used to see how well the model generalizes to new data.
To overcome this situation, the original dataset is split into 3 different sets- ‘training dataset’, ‘validation dataset’, and ‘test dataset’.
The solution to the above issues is to use cross-validation.
It is a process in which the original dataset is divided is divided into two parts only- the ‘training dataset’ and the ‘testing dataset’.
The need of a ‘validation dataset’ is eliminated when cross-validation comes into the picture.
There are many variations of the ‘cross-validation’ method, and the most commonly used one is known as ‘k’ fold cross-validation.
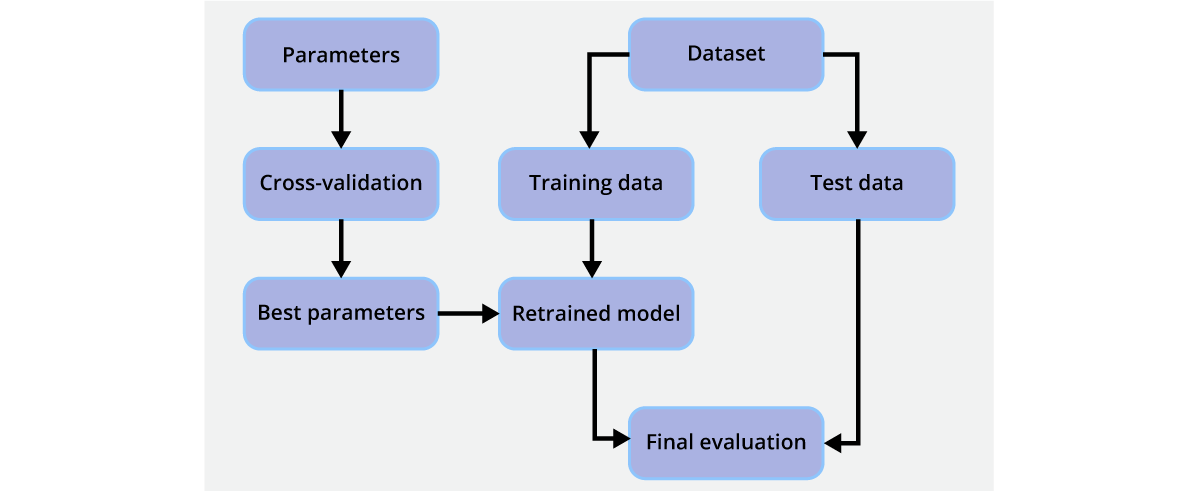
Steps in ‘k’ fold cross-validation
The above image can be used as a representation of cross validation. Once the part of the training set is checked to find the best hyperparameter, and the best hyperparameter/s are found, this new data is again sent to the model to be retrained. The model will also have the knowledge of the old training data, and along with it, it may give better results, and it can be tested by seeing how new data performs on the testing set of this model.
This depends on the data in hand. It is a trial and error method in which the value is chosen. Usually it is taken as 10 which is completely arbitrary. A large value for ‘k’ indicates less bias, and high variance. Also, this means more data samples can be used to give a better, and precise outcomes.
Data required to understand ‘k’ fold cross validation can be taken/copied from the below location:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.data
This data can be pasted into a CSV file and the below code can be executed. Make sure to give heading to all the columns.
Output:
Note:
Instead of using ‘mean’ to find r-squared value, the ‘cross_val_predict’ or ‘cross_val_score’ present in the ‘scikit-learn’ package (model_selection) can also be used. The ‘cross_val_predict’ will give the predictions from the dataset when every split is made during the training. On the other hand, the ‘cross_val_score’ gives the r-squared value using cross-validation.
Code explanation
Here, we are importing the cross_val_predict present in scikit-learn package:
Output:
The above output displays the cross validation prediction in an array.
Code explanation
The ‘cross_val_predict’ function present in scikit-learn package is imported, and the previously generated data is considered, and this function can be called on that same data to see the cross– validation value.
Here, we are importing the cross_val_score present in scikit-learn package:
Output:
The ‘cross_val_score’ function present in scikit-learn package is imported, and the previously generated data is considered, and this function can be called on that same data to see the cross– validation score.
There are variations to cross validations, and they are used in relevant situation. The most commonly used one is the ‘k’-fold cross-validation. Others have been listed below:
Hence, in this post, we saw how ‘k’ fold cross validation eliminates the need to procure a validation dataset and how a part of the training dataset itself can be used as a validation set, thereby not affecting the separate testing dataset. We also saw the concepts of underfitting and overfitting, and how important it is for the model to fit just-right, with the concept of “Hyperparameter” as well. We saw how the ‘k’ fold cross-validation is implemented in Python using scikit-learn and how it affects the performance of the model.
Research & References of The K-Fold Cross Validation in Machine Learning|A&C Accounting And Tax Services
Source