
Machine Learning Model Evaluation
If we were to list the technologies that have revolutionized and changed our lives for the better, then Machine Learning will occupy the top spot. This cutting-edge technology is used in a wide variety of applications in day-to-day life. ML has become an integral component in most of the industries like Healthcare, Software, Manufacturing, Business and aims to solve many complex problems while reducing human effort and dependency. This it does by accurately predicting solutions for problems and various applications.
Generally there are two important stages in machine learning. They are Training & Evaluation of the model. Initially we take a dataset to feed to the machine learning model, and this process of feeding the data to our Designed ML model is called Training. In the training stage, the model learns the behavior of data, capable of handling different forms of data to better suit the model, draws conclusion from the data and finally predicts the end results using the model.
This technique of training helps a user to know the output of the designed machine learning model for the given problem, the inputs given to the model, and the output that is obtained at the end of the model.
But as machine learning model engineers, we might doubt the applicability of the model for the problem and have questions like, is the developed Machine learning model best suited for the problem, how accurate the model is, how can we say this is the best model that suits the given problem statement and what are the measures that describe model performance?
In order to get clarity on the above questions, there is a technique called Model Evaluation, that describes the performance of the model and helps us understand if the designed model is suitable for the given problem statement or not.
This article helps you to know, the various measures involved in calculating performance of a model for a particular problem and other key aspects involved.
This technique of Evaluation helps us to know which algorithm best suits the given dataset for solving a particular problem. Likewise, in terms of Machine Learning it is called as “Best Fit”. It evaluates the performance of different Machine Learning models, based on the same input dataset. The method of evaluation focuses on accuracy of the model, in predicting the end outcomes.
Out of all the different algorithms we use in the stage, we choose the algorithm that gives more accuracy for the input data and is considered as the best model as it better predicts the outcome. The accuracy is considered as the main factor, when we work on solving different problems using machine learning. If the accuracy is high, the model predictions on the given data are also true to the maximum possible extent.
There are several stages in solving an ML problem like collection of dataset, defining the problem, brainstorming on the given data, preprocessing, transformation, training the model and evaluating. Even though there are several stages, the stage of Evaluation of a ML model is the most crucial stage, because it gives us an idea of the accuracy of model prediction. The performance and usage of the ML model is decided in terms of accuracy measures at the end.

We have known that the model evaluation is an Integral part in Machine Learning. Initially, the dataset is divided into two types, they are “Training dataset” and “Test dataset”. We build the machine learning model using the training dataset to see the functionality of the model. But we evaluate the designed Model using a test dataset, which consists of unseen or unknown samples of the data that are not used for training purposes. Evaluation of a model tells us how accurate the results were. If we use the training dataset for evaluation of the model, for any instance of the training data it will always show the correct predictions for the given problem with high accuracy measures, in that case our model is not adequately effective to use.
There are two methods that are used to evaluate a model performance. They are
The Holdout method is used to evaluate the model performance and uses two types of data for testing and training. The test data is used to calculate the performance of the model whereas it is trained using the training data set. This method is used to check how well the machine learning model developed using different algorithm techniques performs on unseen samples of data. This approach is simple, flexible and fast.
Cross-validation is a procedure of dividing the whole dataset into data samples, and then evaluating the machine learning model using the other samples of data to know accuracy of the model. i.e., we train the model using a subset of data and we evaluate it with a complementary data subset. We can calculate cross validation based on the following 3 methods, namely
In the method of validation, we split the given dataset into 50% of training and 50% for testing purpose. The main drawback in this method is that the remaining 50% of data that is subjected to testing may contain some crucial information that may be lost while training the model. So, this method doesn’t work properly due to high bias.
In the method of LOOCV, we train all the datasets in our model and leave a single data point for testing purpose. This method aims at exhibiting lower bias, but there are some chances that this method might fail because, the data-point that has been left out may be an outlier in the given data; and in that case we cannot produce better results with good accuracy.
K-fold cross validation is a popular method used for evaluation of a Machine Learning model. It works by splitting the data into k-parts. Each split of the data is called a fold. Here we train all the k subsets of data to the model, and then we leave out one (k-1) subset to perform evaluation on the trained model. This method results in high accuracy and produces data with less bias.
Predictive models are used to predict the outcomes from the given data by using a developed ML model. Before getting the actual output from the model, we can predict the outcomes with the help of given data. The prediction models are widely used in machine learning, to guess the outcomes from the data before designing a model. There are different types of predictive models:
A Classification model is used in decision making problems. It separates the given data into different categories, and this model is best suited to answer “Yes” or “No” questions. It is the simplest of all the predictive models.
Real Life Applications: Projects like Gender Classification, Fraud detection, Product Categorization, Malware classification, documents classification etc.
Clustering models are used to group the given data based on similar attributes. This model helps us to know how many groups are present in the given dataset and we can analyze what are the groups, which we should focus on to solve the given problem statement.
Real Life Applications: Projects like categorizing different people present in a classroom, types of customers in a bank, identifying fake news, spam filter, document analysis etc.
A forecast model learns from the historical data in order to predict the new data based on learning. It majorly deals with metric values.
Real Life Applications: Projects like weather forecast, sales forecast, stocks prices, Heart Rate Monitoring etc.
Outlier model focuses on identifying irrelevant data in the given dataset. If the data consists of outliers, we cannot get good results as the outliers have irrelevant data. The outliers may have categorical or numerical type of data associated with them.
Real Life Applications: Major applications are used in Retail Industries, Finance Industries, Quality Control, Fault Diagnosis, web analytics etc.
In order to evaluate the performance of a Machine Learning model, there are some Metrics to know its performance and are applied for Regression and Classification algorithms. The different types of classification metrics are:
Classification accuracy is similar to the term Accuracy. It is the ratio of the correct predictions to the total number of Predictions made by the model from the given data.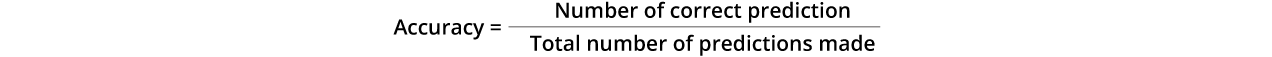
We can get better accuracy if the given data samples have the same type of data related to the given problem statement. If the accuracy is high, the model is more accurate and we can use the model in the real world and for different types of applications also.
If the accuracy is less, it shows that the data samples are not correctly classified to suit the given problem.
It is a NxN matrix structure used for evaluating the performance of a classification model, where N is the number of classes that are predicted. It is operated on a test dataset in which the true values are known. The matrix lets us know about the number of incorrect and correct predictions made by a classifier and is used to find correctness of the model. It consists of values like True Positive, False Positive, True Negative, and False Negative, which helps in measuring Accuracy, Precision, Recall, Specificity, Sensitivity, and AUC curve. The above measures will talk about the model performance and compare with other models to describe how good it is.
There are 4 important terms in confusion matrix:
The accuracy can be calculated by using the mean of True Positive and True Negative values of the total sample values. It tells us about the total number of predictions made by the model that were correct.
Precision is the ratio of Number of True Positives in the sample to the total Positive samples predicted by the classifier. It tells us about the positive samples that were correctly identified by the model.
Recall is the ratio of Number of True Positives in the sample to the sum of True Positive and False Negative samples in the data.
It is also called as F-Measure. It is a best measure of the Test accuracy of the developed model. It makes our task easy by eliminating the need to calculate Precision and Recall separately to know about the model performance. F1 Score is the Harmonic mean of Recall and Precision. Higher the F1 Score, better the performance of the model. Without calculating Precision and Recall separately, we can calculate the model performance using F1 score as it is precise and robust.
Sensitivity is the ratio of Number of actual True Positive Samples to the sum of True Positive and False Positive Samples. It tells about the positive samples that are identified correctly with respect to all the positive data samples in the given data. It is also called as True Positive Rate.
Specificity is also called the True Negative Rate. It is the ratio of the Number of True Negatives in the sample to the sum of True negative and the False positive samples in the given dataset. It tells about the number of actual Negative samples that are correctly identified from the given dataset.
False positive rate is defined as 1-specificity. It is the ratio of number of False Positives in the sample to the sum of False positive and True Negative samples. It tells us about the Negative data samples that are classified as Positive, with respect to all Negative data samples.
For each value of sensitivity, we get a different value of specificity and they are associated as follows:
It is a widely used Evaluation Metric, mainly used for Binary Classification. The False positive rates and the True positive rates have the values ranging from 0 to 1. The TPR and FPR are calculated with different threshold values and a graph is drawn to better understand about the data. Thus, the Area Under Curve is the plot between false positive rate and True positive rate at different values of [0,1].
It is also called Log Loss. As we know, the AUC ROC determines the model performance using the predicted probabilities, but it does not consider model capability to predict the higher probability of samples to be more likely positive. This technique is mostly used in Multi-class Classification. It is calculated to the negative average of the log of correctly predicted probabilities for each instance.
where,
It helps to predict the state of outcome at any time with the help of independent variables that are correlated. There are mainly 3 different types of metrics used in regression. These metrics are designed in order to predict if the data is underfitted or overfitted for the better usage of the model.
They are:-
Mean Absolute Error is the average of the difference of the original values and the predicted values. It gives us an idea of how far the predictions are from the actual output. It doesn’t give clarity on whether the data is under fitted or over fitted. It is calculated as follows:
Bias is the difference between the Expected value and the Predicted value by our model. It is simply some assumptions made by the model to make the target function easier to learn. The low bias indicates fewer assumptions, whereas the high bias talks about more assumptions in the target data. It leads to underfitting of the model.
Variance takes all types of data including noise into it. The model considers the variance as something to learn, and the model learns too much from the trained data, and at the end the model fails in giving out accurate results to the given problem statement. In case of high variance, the model learns too much and it can lead to overfitting of the model.
Conclusion
While building a machine learning model for a given problem statement there are two important stages, namely training and testing. In the training stage, the models learn from the data and predict the outcomes at the end. But it is crucial that predictions made by the developed model are accurate. This is why the stage of testing is the most crucial stage, because it can guarantee how accurate the results were to implement for the given problem.
In this blog, we have discussed about various types of Evaluation techniques to achieve a good model that best suits a given problem statement with highly accurate results. We need to check all the above-mentioned parameters to be able to compare our model performance as compared to other models.

Research & References of Machine Learning Model Evaluation|A&C Accounting And Tax Services
Source