
What is Descriptive Statistics?
Data management is a tedious process. Data mishandling can lead to a vicious circle where eliminating complexities become difficult, sometimes impossible. Therefore, understanding the information regarding a data set is crucial to streamline the decision-making process and analyze data in the long term.
Descriptive statistics describes the elementary characteristics of data by displaying the basic sum-up of a sample or a population. The term descriptive statistics is also applied to display quantitative descriptions in research where there is an involvement of measuring big data.
The classification of statistics are as follows:
Datasets are the distribution of values. The number of occurrences of a particular event in a sequence or a data set is known as frequency. Experts use tables and graphs for calculating the frequency of each likely reading of a variable, extracted in proportions.
Let us understand this with the help of an example:
Scores = 4, 4, 6, 6, 2, 1, 1, 4, 6, 6, 2, 2, 4, 6
No of sixes: 5
No of fours: 4
No of twos: 3
No of singles: 2
Normal distribution
The normal distribution is popularly known as the Bell-curve or the Gaussian distribution. They are symmetric at the Mean, displaying the values close to the Mean more often in occurrence than compared to the data away from the Mean. The normal distribution looks like a bell-shaped curve having the characteristics stated below:
Note: The standard normal distribution contains two parameters, the Mean and Standard Deviation. With a normal distribution, 68% of the readings are in the +/- 1 Standard Deviation of the Mean, 95% are in the +/- 2 Standard Deviations, and 99.7% are in the +/- 3 Standard Deviations.
The diagram below shows you a clear view of a Normal distribution structure.

The normal distribution uses a theory called Central Limit Theorem. The theory explains that Means generated from independent, identically spread random variables have just about normal distributions, irrespective of the method of distribution by which the finite variables are tested.
The central tendency is used to find the central or the middle-value of a dataset. The most commonly used central tendencies are Mean, Mode, and Median.
 Mean
Mean
The Mean is also denoted as M and is the most popular technique of obtaining averages. To find the Mean of the data set, sum up the total values in the sequence, and divide the sum of the values by the number of responses, denoted as N.
Let us understand this with an example:
A person imagines the number of hours in a day he sleeps for in a week. Therefore, the dataset would contain the hours (7,8,8,10,8,6,9), and the total of the values, which is 56 and the number of values, which is 7.
N=7.
We divide 56 by 7 to find the Mean. The result is 8, which is the Mean.
Mode
The Mode is simply the most repeated term in the sequence. We can find the Mode by rearranging our data set in ascending order, which is, from the lowest to the highest. We then find the most repeated term in the entire data set.
Let us understand this with an example:
Sample dataset: 4, 6, 7, 7, 8, 9, 10, 9, 7, 9, 7
Mode = 7 (since it is the most repeated value).
Attention: In our sample data set, it is evident that the number 7 appears the most, and hence we choose 7 as the Mode of the dataset.
Median
The Median is the value in the exact midpoint of a dataset. To obtain the Median, we arrange the values in the ascending order, that is, from the lowest to the highest. We then locate the value in the centre of the set.
Let us understand this with examples:
When N is odd.
When N is even
The measure of Dispersion is mainly used to describe the spread of data. We use Range, Standard Deviation, and Variance to explain the measure of Dispersion.
Range
Range regulates how far away the values are. To obtain the Range, we begin by subtracting the lowest value in a data set from the highest value.
For example,
in the data set (4,6,7,8,8,9,10), 4 is the smallest value while 10 is the highest value. Therefore, we get the Range by subtracting 4 from 10, and that equals 6.
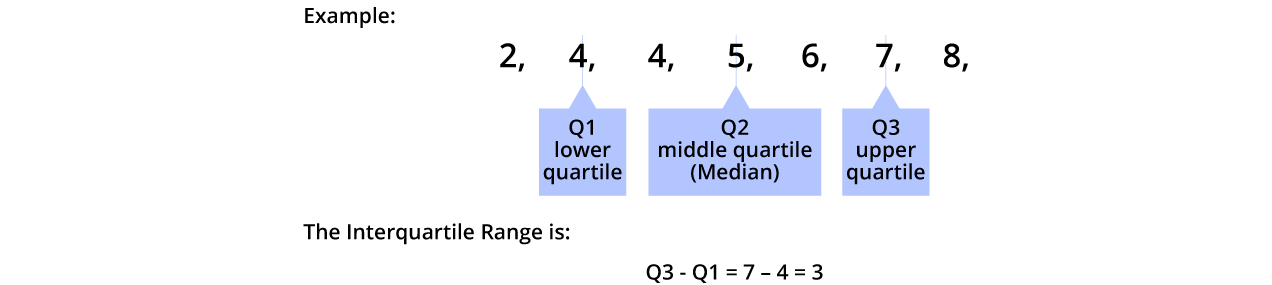
Interquartile Range
The Interquartile Range demonstrates the center 50% of values when sorted in ascending order, that is, from the lowest to the highest. To obtain the Interquartile Range (IQR), we obtain the Mean of the lower and upper half of the dataset. The values are the quartile 1(Q1) and quartile 3 (Q3). Interquartile Range = Q3 and Q1.
The table below shows us a clear view of the Interquartile Range:

Let us understand with the help of an example.
 Variance and Standard Deviation
Variance and Standard Deviation
Variance
Variance mirrors the dataset amount of Dispersion. The Variance is always greater than the Mean when the Dispersion of the data is of a greater extent. We can obtain Variance by simply squaring the Standard Deviation.

Standard Deviation
The Standard Deviation is the Mean of Variability, displaying how far are the values in the sequence from the Mean.
Let us follow the following steps to find the Standard Deviation:
Let us understand this with an example:
When we divide the total of squared Deviations by 6 (N-1): 23.83/6, we obtain 3.971, and the square root of the outcome is 1.992. Through the results, we have noted that every value differs from the Mean by 1.992 average points.
Modality
We can calculate the Modality of the distribution by calculating its total number of Peaks. Several distributions have only one Peak, but we will likely come across distributions with two or more Peaks.
The three types of Modality are:

Skewness
Skewness is the calculation of how a distribution is symmetrical. It demonstrates the extent to which a distribution contrasts from the normal distribution, either to the left or right. The value of skewness of a distribution can be positive, negative, or zero. A skewness of zero implies that the Mean equals the Median.
In the picture below, we can see a better demonstration of the types of Skewness:
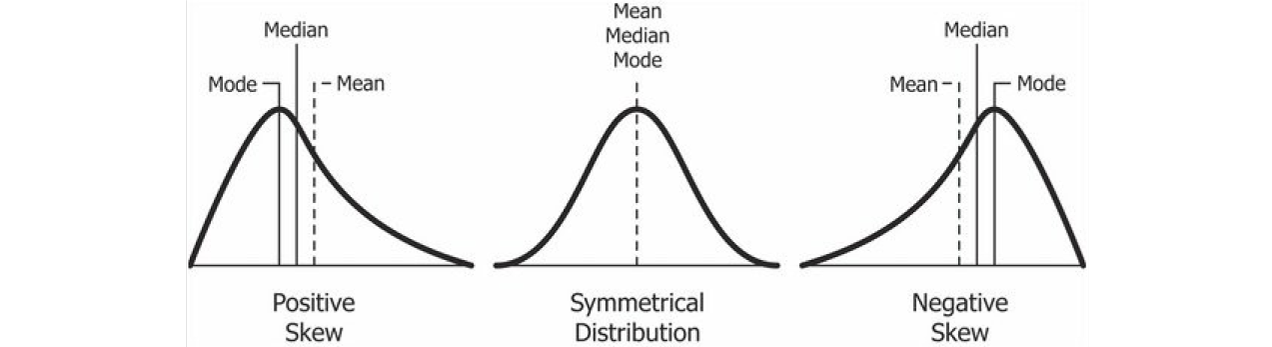
To identify the positive Skew, we notice that most of the data is heaped up to the left. A negative skew on the other side has most of its data heaped up to the right. We need to note that positive Skews are very popular compared to negative Skews. The Skew () function allows us to calculate the Skewness of a distribution.
Kurtosis
Kurtosis estimates the degree to which our dataset is heavy-tailed or light-tailed, contrasted with the normal distribution. Datasets that contain high Kurtosis have high tails and many outliers, while datasets containing low Kurtosis have light tails and less outliers. Histogram and Probability are the operative ways to show the Skewness and Kurtosis of datasets.
Fisher’s measurement of Kurtosis arithmetically and efficiently calculates the Kurtosis of a distribution.

Kurtosis has three main types:
Summary
This article has given us a comprehensive introduction to the various terms used in descriptive statistics. We have focused on the areas of normal distribution and their advantages. The commonly used measures of descriptive statistics were also explained with suitable examples. After understanding the descriptive statistic in-depth, we know how the data gets analyzed. We should keep in mind that descriptive statistics does not allow any conclusions to be made on data analysis, rather, it is a measure that describes the data.
Research & References of What is Descriptive Statistics?|A&C Accounting And Tax Services
Source